For a while I’ve been working on a project in V8 to encode type feedback into simple data structures rather than embedding it in compiled code.
The V8 inline cache system typically compiles a “dispatcher” which checks an incoming object map against a constant. If there is a match, control is dispatched to a handler, which may be a stock stub or be specially compiled for this object. The inline cache (IC) patches this dispatcher code into a compiled function. The dispatcher improves performance, because many decisions have been reduced to a comparison of a map against a constant (we call this a map check). We can also examine the dispatcher later for it’s embedded maps to determine what it knows when creating optimized code.
After this thumbnail sketch of how ICs work (here is a much better one), you may think, why change it? Well, it would be nice to avoid patching code for security reasons and the fact that it causes a flush of the instruction cache which hampers performance on some platforms. Storing our maps in arrays is natural and makes extending the information we collect easier. For example, we might want to store polymorphic call counts. When we use a data structure, we can just store a triple for each map: the map, the “handler” that we jump to, and finally an integer count. That could be used later to order polymorphic calls. You might even coalesce this data by shunting rarely used maps to a generic handler and therefore reduce the degree of polymorphism.
So that’s why it would be nice to embed information in data structures rather
than code. But the V8 IC system is rich, complex and performance
sensitive. Becuase of that introducing data structures for feedback has been
slow. A year ago I began using the “type feedback vector” to record data for
calls from one JavaScript function to another. Now I’m working on making loads
(like x = obj.foo and keyed loads like x = obj[h]) use the type
feedback vector, and avoid patching code completely.
It’s difficult because a data structure solution means more memory loads no matter how you slice it. Here we come to another potential beneft of a type vector: it could be used in optimized code for which we only have partial type feedback. Normally, V8 will deoptimize an optimized function if it begins running a section for which we never ran before in full code. This could happen if the function is considered “hot” but there is a branch that was never yet taken. With the type feedback vector, we could install vector-based ICs in those information-poor locations, allow them to learn for a while, then reoptimize after achieving a certain threshold of new information.
Deoptimizing functions is expensive for V8, and I’ll go into that more later - it’s just a tremendous amount of work and complexity. Type vectors offer the possibility to smooth out and moderate the optimized/un-optimized transition curve over the lifetime of an application.
So that is my motivation. V8 is using the type vector for call ICs as mentioned, but loads are the important case because there are so many of them. If that can be achieved, then we have license to go the rest of the way and eliminate patching entirely. It’s a tremendously fun project.
I’ve been writing this document as I learned about the area, and was inspired by Vyacheslav Egorov’s article explaining inline caches in a readable and entertaining way. I loved the way his drawings looked, as it reminded me of the only way I seem to be able to internalize most concepts: by drawing them on paper. Vyacheslav built a tool to create attractive “box and pointer” drawings from ASCII, and I started using it to think about the process along the way. Creating these pictures because a major part of the fun in the last few days :D.
Too many loads
I’ve already spent time micro-optimizing my data-driven dispatcher, which grovels about in the vector to complete it’s map-checks and dispatches. That is the subject of another article, but suffice to say here that when I’m contemplating doing 2 levels of speculative reads into data carefully constructed to guarantee crash avoidance, just in order to save one additional read…I’ve probably hit the end of the line for that activity.
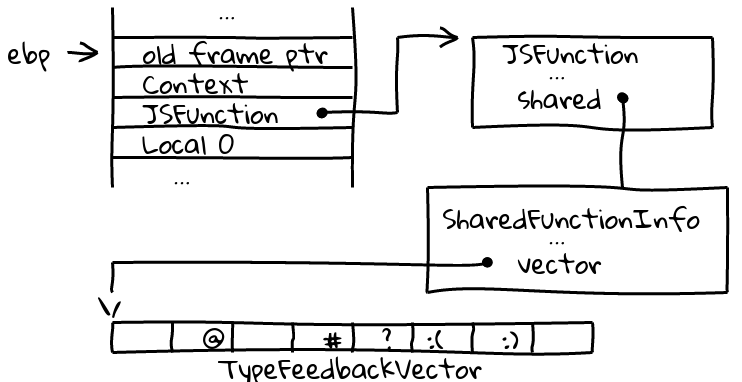
Now I turn to the number of reads required before the call to the dispatcher. The type vector is an array attached to the SharedFunctionInfo for a JavaScript function. It’s indexed by a “slot,” and these slots are handed out at compilation time to compilation nodes that request them. The IC receives a pointer to the vector and an integer index into the vector (the index is derived from the slot but not the same thing).
Fair enough, but how do we load the vector into a register for the call? I could
just embed it in the code, as it’s a constant, but experimentally, this changed
the code size so much even just when using it for calls, that it would bloat the
code unacceptably if I do this for all IC types. It threw off our profiler
calculations, highlighting a weakness there that the profiler is based on code
size in bytes rather than say, number of abstract syntax tree nodes (this should be tackled and
solved, of course!). What proved a better solution for production was a series
of loads. The JSFunction associated with this function is available in the
stack frame. I load that, then walk through to the vector hanging off the
SharedFunctionInfo. It seems that these loads aren’t too expensive because the
data is in the cache.
But for wider deployment of the type vector concept, this many loads becomes hard to support. Consider function foo:
function foo(obj, x) {
for (var i = 0; i < x.length; i++) {
x[i] = x[i] * i + obj.foo;
check(i);
}
}The expressions x.length, the second x[i], obj.foo, and
check(i) all need the type vector. Just considering that the vector needs 3
loads, that is 3 * 4 * x.length loads.
Ideally, we would just have 3 loads, by hoisting the vector load out of the
loop. But that involves more architecture than we want to invest in full
code. Usage of the type vector in optimized code isn’t supposed to be very
heavy, but by introducing the vector as a node in those compilations we’ll get
that kind of hoisting there. But I can reduce the number of loads by storing the
feedback vector in the frame, meaning we’ll have 4 * x.length loads (or at
least until the profiler decides the function is hot enough and drops in an
optimized version in place via on-stack-replacement (OSR), which is a fantastic
thing).
Whats more, these loads are all from a stack address in the frame and should remain in
the cache.
This means I’ll have to alter the frame layout. Gulp.
Unoptimized JavaScript frames get a Vector
First off, why only add the vector to unoptimized JavaScript frames? Well, an optimized JavaScript frame actually contains many vectors, one for each function that it inlines. The vector for the ostensibly optimized function is only partially useful, and couldn’t be referred to by any of the inlined functions. Of course, there could be a load/restore step surrounding inlined calls, but that seems like a lot of work in code that should be tight, and ideally, shouldn’t use the type vector at all. Ideally we’ve learned from all ICs seen thus far. Also, if we need to refer to a type feedback vector in optimized code, we could let sophisticated technologies like GVN and the register allocator decide where to put the constant vector address and when to load it.
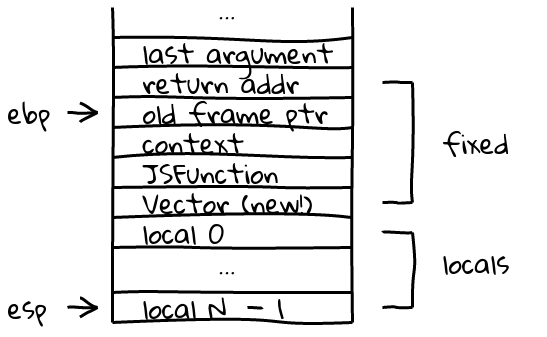
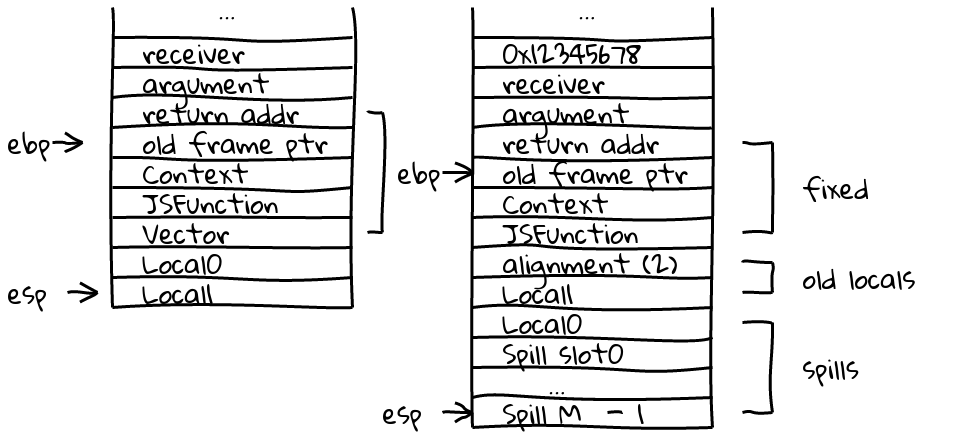
Therefore, here is a V8 JavaScript Frame, with a type vector field added just after the JSFunction. The stack is positioned just before making a call to another function:
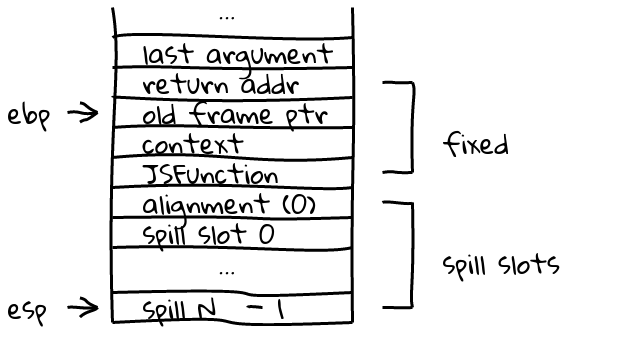
An optimized frame looks a bit different. There is no vector, but there is an alignment word on 32 bit platforms that indicates whether the stack has been aligned or not. Here is a case where no alignment occurred, and just before a call to another function:
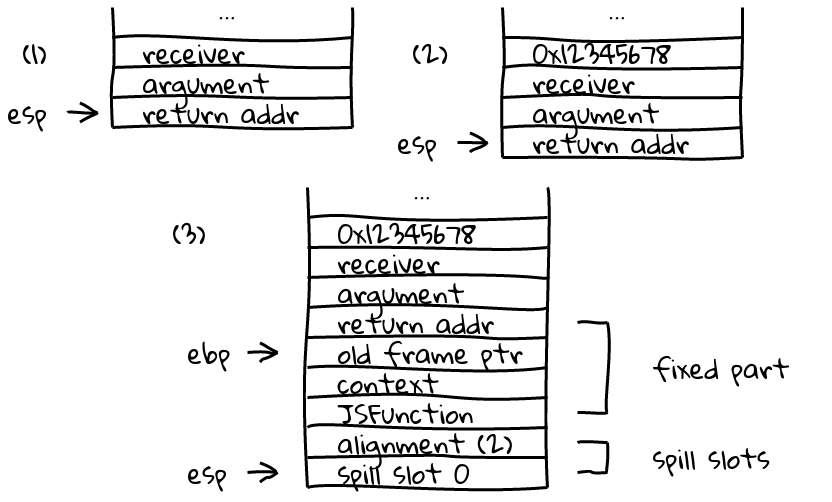
Alignment introduces some complication. When we are about to save the previous
$ebp to the stack, we check to see if $esp is aligned. If so, we proceed
normally, saving the value 0 in the alignment slot in the frame. Otherwise,
we’ll move the receiver, arguments and return address down one word on the
stack, putting a “zap value” (0x12345678) where the receiver used to be. Then in the
alignment slot we’ll store the value 2 as a signal when it’s time to dismantle
the frame. When we encounter that value on return, we know we need to clear one
more word from the stack on return (the “zap value”). We have to read the
alignment slot before we dismantle the frame, then after taking the frame down
we have to take care of the receiver and arguments. The example below is a
function with one argument, and a receiver. The
optimized frame just has one real spill slot, the other is reserved for the
alignment word.
The need for alignment of an optimized frame is recognized on entry, before setting up the frame. A “zap value” is inserted and the stack values get moved down one word. In step (3), the optimized frame has been built, and the alignment word contains the value 2 as a hint that the zap value also needs to be popped from the stack on return.
Deoptimization
If an optimized function needs to deoptimize, then it’s frame needs to be
translated into several output frames, since a single optimized function may
contain many inlined functions as well. We end up with one InputFrame and
several OutputFrames.
Let’s take an optimized function with no arguments that deopts on entry. The
function has two spill slots, one for the alignment word. The deopt process is
begun with a call to a function that pushes a Bailout ID. The
deoptimization function then pushes registers to the stack and prepares to
create a Deoptimizer object.
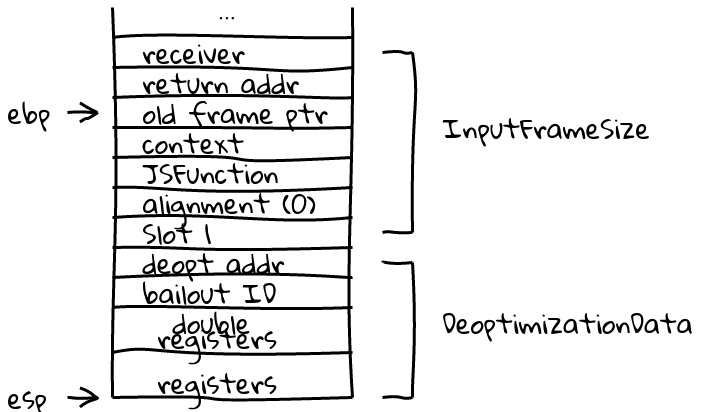
The function has deopted, and is preparing to create the Deoptimizer object. All
of the necessary information is on the stack. This information is used to build the Deoptimizer. We then unwind the whole
stack, copying all the registers and then the frame to the input
FrameDescription object allocated when the Deoptimizer was created. At this
point we go to C++ and compute all of the output frames. After this,
we check the alignment word, and pop off the alignment “zap
value” if it’s present (not in the example above). We end up at a completely
empty stack, with no way to do anything or go anywhere, because we’ve even
popped off the return address.
We loop over all the output frames, pushing their contents to the stack from the higher (deepest) addresses to the lower (most shallow) addresses:
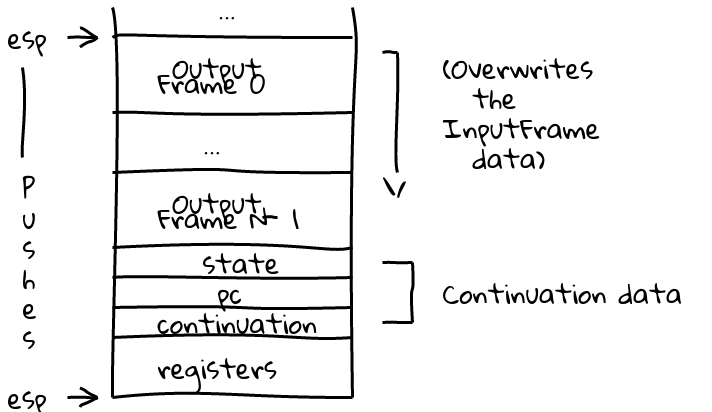
The OutputFrames have been computed, and are being copied to the stack in the appropriate place. Finally, continuation data and register state are propped to the stack. We’ll pop the registers into place, return to the continuation address, and finally state and pc are consumed to deposit us rather prettily into frame N-1.
With a popad instruction, we
restore the saved registers to the CPU, then
execute a ret instruction to pop the continuation address from the stack
and jump to it’s code. The state and pc addresses will be consumed to
appropriately enter unoptimized code at the right point with the right
registers. The stack will gradually unwind correctly.
The output frames have a different fixed size thanks to the addition of the type feedback vector in full-code JavaScript frames. Here is a side-by-side translation of the bottom-most frame in a one argument, non-aligned example where the output frame has no locals:
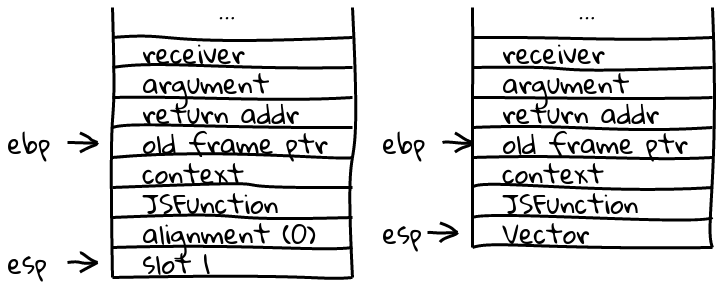
Alternatively, if the bottom-most optimized frame was aligned, we’d have to remove the alignment zap value and shift values to higher stack addresses (forgive me for focusing so much on alignment…it was rather a bear):
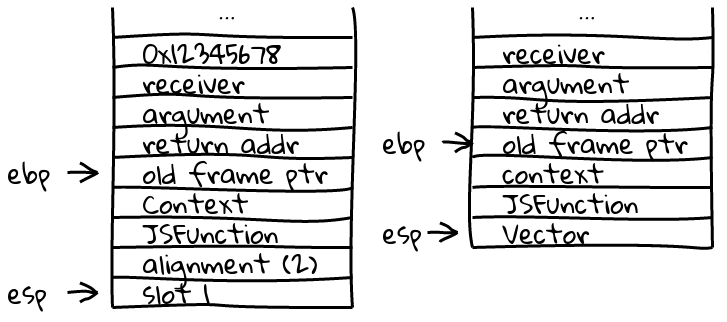
An aligned, optimized InputFrame gets replaced on the stack like so. Note that the output frame is the same as that in the previous unaligned case.
On Stack Replacement (OSR)
If we run a tight loop, we may want to optimize and replace code before we finish. This means optimizing and installing our optimized frame over the current frame. In fact, we think of simply appending the new parts of our new frame to the end of the existing JavaScriptFrame. Optimized frames have spill slots. These will go right after the locals of the frame already there. The first job on entry to the optimized code (mid-loop, how exciting!) is to copy those locals into spill slots where the register allocator can track them.
I altered the OSR entry point to shift those locals up one word on the stack, overwriting the vector slot from the unoptimized frame. My first approach, which ended in a hail of mysterious test failures was to leave the vector in place, and try to get the optimizing compiler to treat it as an “extra” spill slot. This became very complicated. For one thing, the deoptimizer had to figure out if it was deoptimizing a function with OSR entries or not, and do the right thing with the “extra” word in the former case. Also, Crankshaft optimized functions with an OSR entry can later be entered from the start, and this starting prologue would have to push an extra dummy value in order to remain in sync with the offsets to locals and spill slots established at the OSR entry point. Life was way better when I abandoned this approach!
Consider also that optimized frames want to be aligned, so the replacement of code to use OSR also means moving the existing parts of the frame. Here is an example, showing the unoptimized stack on the left, and the optimized one on the right. In the before/after diagram, note that the fixed part gets smaller with the removal of the vector in the optimized frame:
Virtual deoptimization for the debugger
We have a test debug-evaluate-locals-optimized.js which verifies that the
debugger can interpret locals and arguments of all functions on the stack, even
if some of the functions are optimized. The example sets up a series of calls
from function f down to function h and invokes the debugger in
function h to verify expected values.
Function Locals Notes
f a4 = 9, b4 = 10 call g1 (inlined in f, argument adapted)
g1 a3 = 7, b3 = 8 call g2 (inlined in f, constructor frame and
argument adapted)
g2 a2 = 5, b2 = 6 call g3 (inlined in f)
g3 a1 = 3, b1 = 4 call h (not inlined)
h a0 = 1, b0 = 2 breakpointThe deoptimization infrastructure is used by the debugger to compute and store
these local values in a data structure for later perusal. We “deoptimize”
function f without actually doing so, but only to harvest the output
frames created in a buffer from that process. f decomposes into 7 output
frames. Here is the input frame layed out on the stack from the call
f(4, 11, 12), and on the right is the bottommost output frame representing
the unoptimized function f:
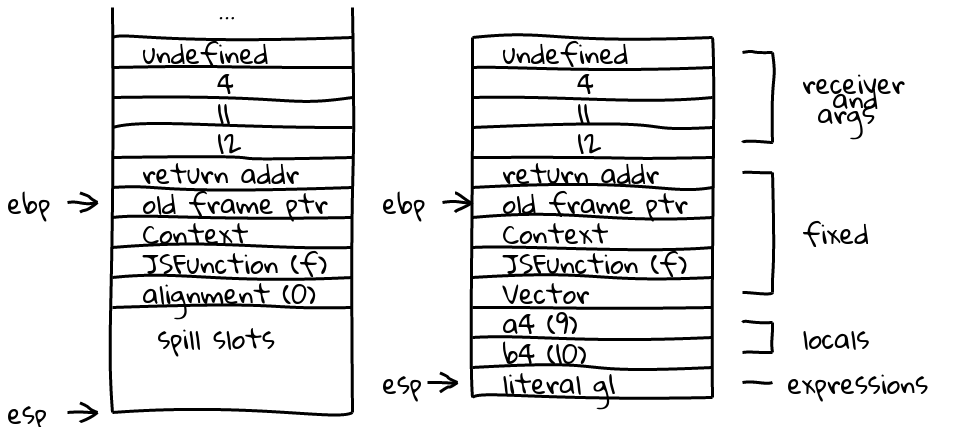
The locals and parameters for the full code frame of f can be queried
according to known frame layouts.
Note the literal g1, which is on the stack, not part of the locals, but simply
an expression saved before the call out to g1. Below are the remaining interesting
OutputFrame data structures, one each for g1, g2 and g3. In the g1 frame, I expected to
see a literal expression for the call to g2 on the stack and was initially
worried about a bug. However g2 is called with new g2(...), and constructor calls
don’t push an expression onto the stack before the call.
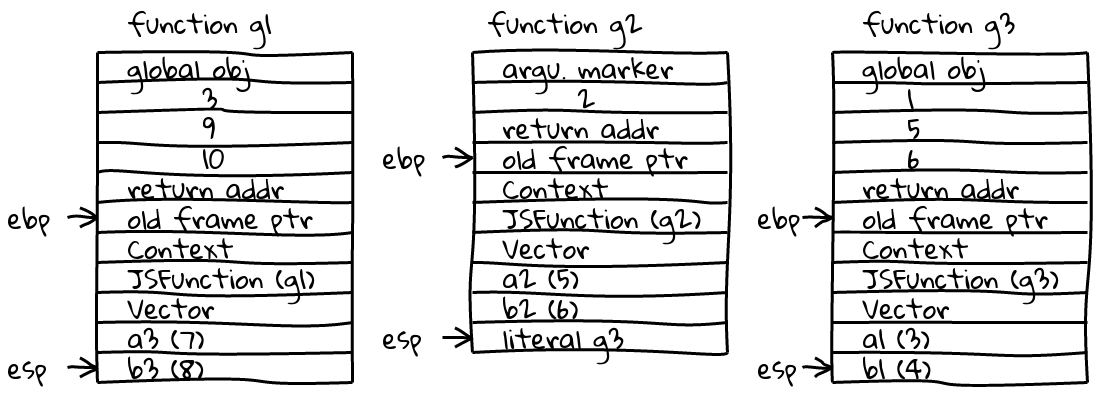
g2 is called with 3 arguments, but it only accepts one so an arguments adaptor
frame is inserted (not displayed here). g3 is called with three arguments as
expected, so no adaptor frame is inserted. In total, 7 OutputFrames are computed:
- f
- arguments adaptor
- g1
- constructor frame
- arguments adaptor
- g2
- g3
Now we start copying this information into a data structure for debugging. First
we examine the frame for g3.
Although my changes in the deoptimizer resulted in correct OutputFrames, the
interpretation was broken. I had to change the FrameDescription class to
return local offsets correctly according to whether it was describing an
OPTIMIZED frame or a JAVA_SCRIPT frame. This would correctly reflect the
variation I’ve introduced with the type feedback vector. With that change made,
the test passes, finding all of the local variables with their correct values.
Conclusion
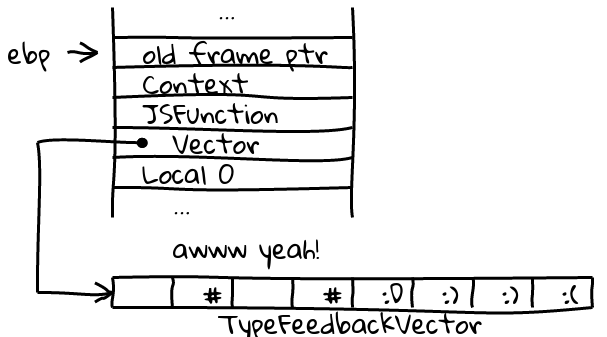
Well, this picture shows I get what I want if the system in is place:
But how about performance? It looks good for most benchmarks, but there are a few SunSpider tests that are short enough that we don’t manage to run optimized code, and there is a net loss because our unmanaged frames are 1 word bigger. I do have to pay for that. Before making this part of the tree, I’ll need to validate that the cost is worthwhile when considering the type vector passage as a whole. On the whole, I’m optimistic.
My changelist for the work on all platforms is here. Thank you for following this meandering course through some V8 internals :).